如何用 AI 给动漫配音,并保持自然口型同步
学习如何用 AI 给动漫配音,并通过角色配音、场景内台词生成、同步预览与多语言交付,让口型同步更自然。
2026年3月13日

学习如何用 AI 给动漫配音,并通过角色配音、场景内台词生成、同步预览与多语言交付,让口型同步更自然。
2026年3月13日
作者:Yihui,MkAnime 创始人
只有漂亮的动漫画面,还不足以真正完成一条短片。
最后一段流程,往往才是最容易变乱的地方。
很多创作者都能把画面生成出来,但一旦开始加对白、声音和口型同步,工作流就会开始断裂。音频在一个工具里处理,嘴型同步在另一个工具里处理,最终预览又在别处完成。即使每一步单独看起来都能工作,整个场景仍然常常失去连贯感。
这也是为什么配音如此重要。
好的动漫配音,不只是把语音叠到视频上,而是让声音和画面像属于同一个场景。

大多数 AI 配音问题,真正出错的并不是声音本身,而是工作流本身。
常见问题通常长这样:
这也是为什么频繁切工具会这么痛苦。每一次交接,都会让最终场景更难控制。
更好的系统会让声音、同步和预览都尽量贴近分镜和项目上下文。这正是 AI Anime Lip Sync 真正有价值的地方。

如果同一个角色每次开口都像不同的人,观众会立刻注意到。
这也是为什么声音选型应该发生在角色层,而不是只在单个场景层处理。
在生成最终对白之前,先决定:
当你的项目包含下面这些情况时,这件事尤其重要:
稳定的声音档案,对音频的意义就像参考表对视觉的意义一样。它会让角色听起来更可识别。

很多配音工作流出问题,是因为台词太早被抽离出了项目。
台词单独写,声音单独做,最后再塞回场景里。这样会更难判断语气、时机和贴合度。
更强的工作流会把配音留在项目上下文里完成。这意味着声音会被下面这些因素共同塑造:
这也是为什么 MkAnime 的配音流程会比普通 TTS 叠加更有整体感。场景、角色和声音保持连接,而不是被拆开处理。
口型同步不应该是你最先解决的问题。
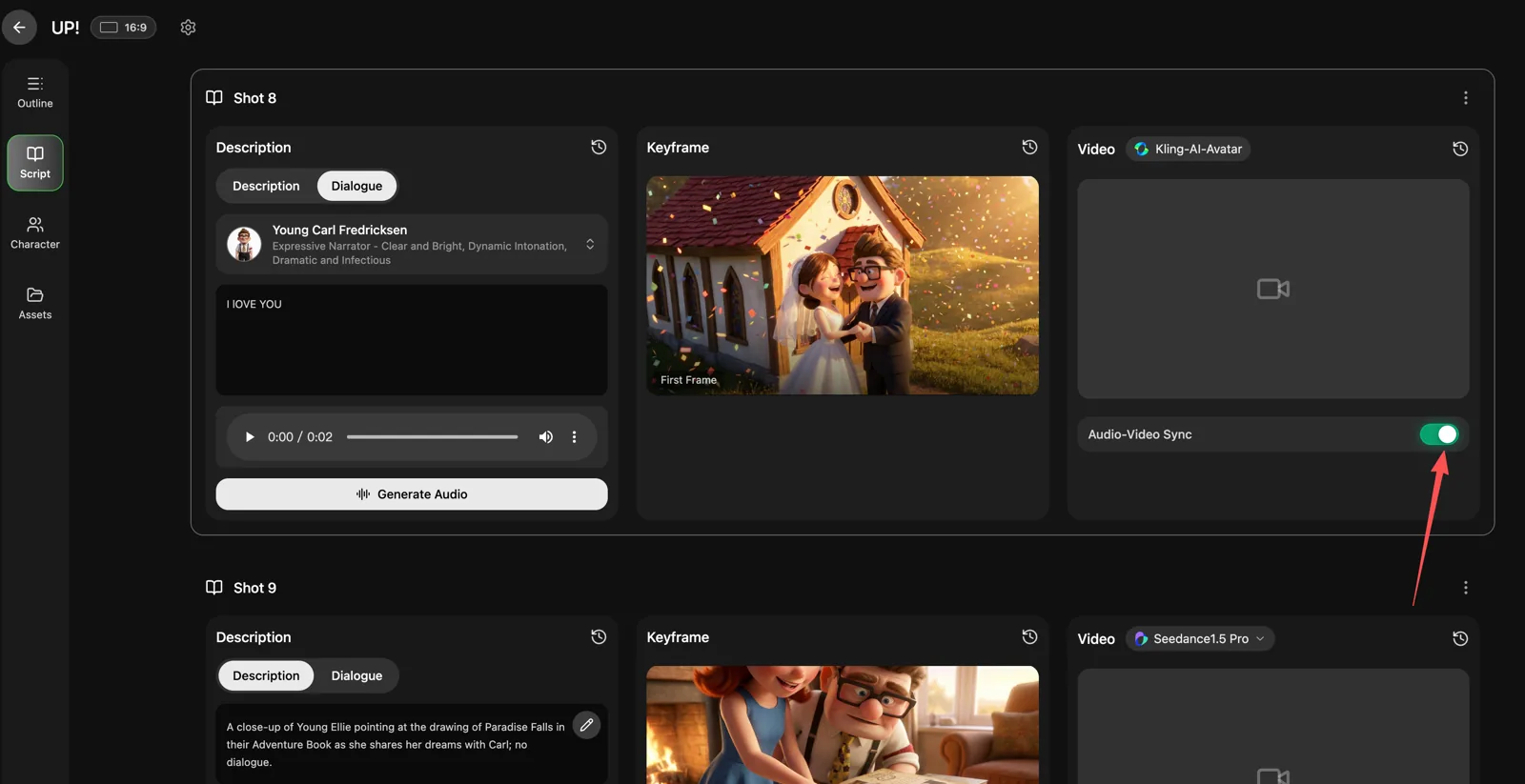
如果分镜还在变、镜头时长还在动,或者场景节奏还不稳定,口型同步只会变成额外清理工作。
更合理的顺序是:
这个顺序非常重要。场景一旦稳定,口型同步就会变成最后的表演层,而不是后期补救层。
这也是很多创作者节省时间的地方。如果你能在导出前先把声音和画面一起预览,很多真正的问题会更早暴露:
这远比等整条短片都拼完之后才发现问题要好得多。

如果你想把动漫短片发布成多个语言版本,工作流会很快变得混乱。
很多创作者最后都会为每个语言版本重建一次音频流程。
更好的方式是复用同一套场景工作流,只替换语言层,而不破坏其他部分。这在声音设定、场景上下文和同步已经挂在项目上的前提下,效果最好。
这对下面这些场景尤其有用:
如果从一开始就把多语言配音纳入计划,你会比后期再补救节省得多。

如果你想让配音更干净、口型同步更自然,先检查这些基础项:
自然的配音通常来自连接,而不只是音质。
如果声音选型、台词生成、口型同步和预览都发生在不同地方,最终场景就很容易有“拼接感”。即使声音本身还不错,表演也不会真的贴在画面上。
MkAnime 的目标,是让声音和画面留在同一个项目工作流里:为持续角色分配声音档案,生成有上下文的台词,把它同步回场景,再在导出前预览配音结果。

这才是让最终场景更连贯的关键。
如果你想用 AI 给动漫配音并保持自然口型同步,关键并不只是找到一条好声音,而是建立正确的执行顺序。
尽早分配角色声音,在场景上下文里生成台词,等视觉流程稳定后再补口型同步,并在导出前把整段场景一起预览。
这是让动漫配音场景更干净、更自然、也更容易真正发布出去的最简单方法。
如果你想在同一条工作流里完成这件事,可以试试 MkAnime 的 AI Anime Lip Sync。
从灵感到分镜,快速创作你的故事